Emparejamiento ELO: por qué gana la habilidad [2026]
El emparejamiento ELO empareja los duelos de LearnClash por habilidad para que cada uno caiga en la zona de dificultad deseable donde se forma la memoria.


Los duelos ELO emparejados por habilidad en LearnClash tienden a una tasa de victoria equilibrada. El emparejamiento aleatorio no. Ni de cerca.
Una tasa de victoria emparejada por ELO es la probabilidad de ganar cuando ambos jugadores comparten una diferencia de puntuación estrecha. En LearnClash, el emparejador compuesto puntúa los duelos abiertos al 50% de proximidad ELO más 50% de similitud de coseno de categoría, ponderado por igual, sin filtro duro de rango. El equilibrio que emerge es la zona de dificultad deseable que la investigación en aprendizaje describe desde hace más de 30 años.
Abajo: las matemáticas detrás de la franja equilibrada, por qué «el 50 forzado» es el marco equivocado, cómo la calibración del K-Factor y el solapamiento de temas dan forma a los emparejamientos, y cómo un emparejamiento ajustado amplifica la retención Mems de 3 etapas. Prueba un duelo LearnClash de 3 minutos y siéntelo tú mismo.
¿Qué es una tasa de victoria emparejada por ELO?
Una tasa de victoria emparejada por ELO es el porcentaje de duelos que esperas ganar emparejado con un oponente de habilidad similar. En LearnClash, esa cifra se agrupa alrededor del 50% porque el emparejador elimina la diferencia de puntuación que la empujaría más arriba o más abajo.
 Figura 1: un duelo emparejado por ELO se sitúa por definición en el 50% de probabilidad de victoria. Añade una diferencia de 400 puntos y la matemática colapsa al 9% para el jugador peor puntuado.
Figura 1: un duelo emparejado por ELO se sitúa por definición en el 50% de probabilidad de victoria. Añade una diferencia de 400 puntos y la matemática colapsa al 9% para el jugador peor puntuado.
La fórmula de puntuación esperada que Arpad Elo publicó en 1960 es muy simple. La probabilidad de victoria de cada jugador viene de la diferencia de puntuación, no de un dial externo. Sin cuotas. Sin mano oculta. Sin impuesto invisible a una racha de victorias.
Punto clave: la franja del 50% que ves es la matemática, no la instrucción. Dos puntuaciones iguales devuelven 0,5 para ambos. Una diferencia de 400 puntos lleva al jugador más fuerte a 0,91 y baja al más débil a 0,09.
| Escenario | ELO jugador A | ELO jugador B | Victoria esperada de A |
|---|---|---|---|
| Igualdad | 1300 | 1300 | 50% |
| Ligero favorito | 1400 | 1300 | 64% |
| Favorito claro | 1700 | 1300 | 91% |
| Underdog | 1300 | 1700 | 9% |
«La puntuación de un jugador es un número que puede usarse como índice de capacidad de rendimiento. Su propósito es proporcionar un método justo de hándicap.» Arpad Elo, The Rating of Chessplayers, Past and Present (1978)
LearnClash hereda las matemáticas detrás del ELO y superpone un emparejador compuesto. El compuesto puntúa duelos abiertos en dos ejes a la vez. Proximidad de habilidad. Relevancia de tema. El emparejamiento minimiza tanto la diferencia de puntuación como la deriva de categoría, así la franja sigue estrecha incluso cuando el tema cambia entre rondas.
¿Sabías que…? Pelanek (2016) validó los emparejadores tipo ELO para educación adaptativa. Duolingo adoptó un sistema estilo Pelanek internamente y reportó un 12% más de actividad diaria.
Un duelo equilibrado es el motor. Un duelo desequilibrado es una fase de calibración o un borde de solapamiento de temas. El resto del artículo desglosa por qué uno se siente genial y el otro roto, y por qué la franja equilibrada de la que se quejan los jugadores de MOBA es la misma franja que cualquier juego de aprendizaje bien diseñado quiere a propósito.
Por qué la franja equilibrada es la función, no el bug
Una franja equilibrada de tasa de victoria es el resultado natural de la competición emparejada por habilidad. En LearnClash, esa franja es la zona de dificultad deseable donde el recuerdo se convierte en memoria duradera. Las victorias fáciles enseñan casi nada. Las derrotas aplastantes enseñan menos. El medio es donde el cerebro trabaja.
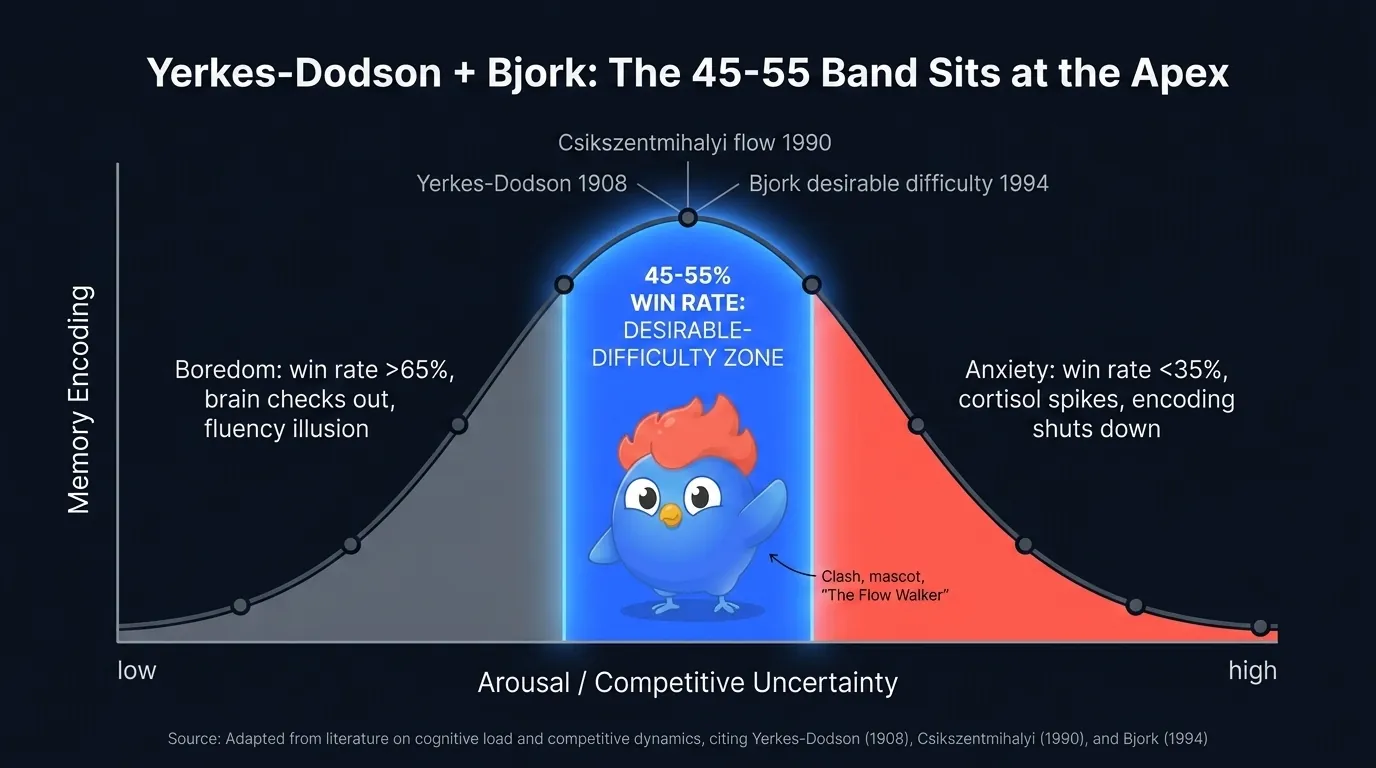 Figura 2: la curva Yerkes-Dodson mapea activación a rendimiento de aprendizaje. Los duelos reñidos y emparejados por ELO se sientan en el ápice; las derrotas aplastantes en cualquier dirección colapsan el lift de codificación.
Figura 2: la curva Yerkes-Dodson mapea activación a rendimiento de aprendizaje. Los duelos reñidos y emparejados por ELO se sientan en el ápice; las derrotas aplastantes en cualquier dirección colapsan el lift de codificación.
Busca en cualquier foro MOBA en español. Encontrarás la misma teoría conspirativa en todas partes:
- Riot fuerza el 50%
- Dota 2 te limita
- Apex Legends frena tus victorias
La queja es más vieja que el emparejamiento por habilidad. Aparece en cada blog dev de Riot durante una década.
Pero hay un fallo en la queja.
Punto clave: un emparejamiento justo produce un resultado justo. Dos jugadores iguales no pueden evitar tender al 50% en cientos de partidas. El sistema no eligió la tasa de victoria. Las habilidades lo hicieron.
En un contexto de aprendizaje, eso pasa de sospechoso a óptimo. Tres corrientes de la ciencia cognitiva convergen en la tasa equilibrada como óptimo:
- Ley de Yerkes-Dodson (1908): la activación moderada produce el mejor encoding
- Flujo de Csikszentmihalyi (1990): el balance reto-habilidad dispara la atención absorta
- Dificultad deseable de Bjork (1994): el recuerdo que apenas tiene éxito refuerza huellas
«Las condiciones que producen un rendimiento más lento o más sujeto a errores durante el aprendizaje a menudo llevan a una mejor retención a largo plazo.» Elizabeth y Robert Bjork, Making Things Hard on Yourself (2011)
La U invertida de Yerkes-Dodson es la más antigua de las tres. Muy poca activación, te desconectas. Demasiada, te bloqueas. En un duelo, esa activación viene de la incertidumbre competitiva. Una paliza en cualquier dirección colapsa a una línea plana. Una pelea 50-50 sigue interesante hasta la última pregunta.
 Figura 2b: la ilusión de fluidez. Las victorias fáciles se sienten como dominio, pero el cerebro apenas codifica la respuesta. El límite del recuerdo, en un duelo reñido, es donde realmente se forman las huellas de memoria.
Figura 2b: la ilusión de fluidez. Las victorias fáciles se sienten como dominio, pero el cerebro apenas codifica la respuesta. El límite del recuerdo, en un duelo reñido, es donde realmente se forman las huellas de memoria.
El canal de flujo de Csikszentmihalyi mapea la misma forma a la atención. El flujo solo emerge cuando el reto percibido se sitúa al borde de la habilidad percibida. Bajo el borde, aburrimiento. Sobre el borde, ansiedad. El sweet spot es estrecho, y el emparejamiento ELO es el algoritmo que lo encuentra.
Así que los jugadores de MOBA tienen razón en que el sistema empuja las tasas de victoria hacia 50. Se equivocan en pensar que es un problema. En LearnClash, ese es exactamente el punto. Queremos que cada duelo caiga en la zona donde tu cerebro codifica la respuesta, no donde te aburres o te bloqueas.
¿Cómo puntúa el emparejador compuesto de LearnClash un duelo?
El emparejador compuesto de LearnClash puntúa cada duelo abierto en una mezcla ponderada 50/50. La proximidad ELO mide cuán cerca están dos puntuaciones. La similitud de coseno de categoría mide el solapamiento de temas. La puntuación combinada decide si un emparejamiento se dispara o sigue en cola.
 Figura 3: el puntuador compuesto recompensa tanto la cercanía de habilidad como la relevancia de tema. Una diferencia ELO de 40 puntos con fuerte solapamiento se dispara; la misma diferencia sin solapamiento espera en cola.
Figura 3: el puntuador compuesto recompensa tanto la cercanía de habilidad como la relevancia de tema. Una diferencia ELO de 40 puntos con fuerte solapamiento se dispara; la misma diferencia sin solapamiento espera en cola.
El eje de habilidad es directo.
La proximidad ELO puntúa 1,0 con cero diferencia. Decae suavemente hasta 0 con una diferencia de 400 puntos.
¿Sabías que…? Una diferencia de 40 puntos devuelve 0,96 en la curva. Una diferencia de 100 puntos devuelve 0,86. Una diferencia de 200 baja a 0,5.
El eje de relevancia es lo que la mayoría de emparejadores se saltan. La similitud de coseno de categoría trata el historial reciente de temas de cada jugador como un vector. El coseno devuelve 1,0 cuando ambos han jugado las mismas categorías. Devuelve 0 cuando no comparten nada.
| Diferencia | Proximidad ELO | Comentario |
|---|---|---|
| 0 | 1,0 | Misma puntuación |
| 40 | 0,96 | Compuesto se dispara fácil |
| 100 | 0,86 | Compuesto se dispara con tema coincidente |
| 200 | 0,50 | Compuesto necesita tema fuerte |
| 400 | 0,00 | Compuesto bloquea el emparejamiento |
Ejemplo trabajado:
| Jugador A (1340 ELO) | Jugador B (1380 ELO) | |
|---|---|---|
| Temas recientes | Europa, geografía, música clásica | Europa, geografía, cine mundial |
| Diferencia ELO | n/a | 40 puntos |
| Proximidad ELO | n/a | 0,96 |
| Coseno de categoría | n/a | 0,83 |
| Puntuación compuesta | n/a | 0,90 |
| ¿Empareja? | n/a | Sí (sobre 0,85) |
La restricción doble es lo que estrecha la franja: un emparejamiento tiene que estar cerca en puntuación y alineado en tema antes de que el compuesto supere el umbral de disparo, así que la mayoría de los duelos que se disparan están equilibrados en habilidad y son relevantes en tema.
El compuesto está ponderado por igual a propósito. El emparejamiento ELO puro ignora la competencia por tema. Un especialista en historia de nivel Fénix aplastaría a un especialista en física de nivel Fénix en la categoría equivocada. El emparejamiento puro por tema ignora la calibración de habilidad. Dos principiantes con intereses idénticos nunca verían ganancias de aprendizaje.
Punto clave: un emparejador compuesto recompensa tanto habilidad como coincidencia de tema. Sin coseno de categoría, el emparejamiento ELO solo no puede garantizar un duelo aprendible.
Qué empuja un duelo fuera de la franja equilibrada
Un duelo de LearnClash emparejado por habilidad tiende a una expectativa de victoria equilibrada, pero tres fuerzas empujan duelos concretos hacia las colas. Cada una es una propiedad del sistema, no un bug.
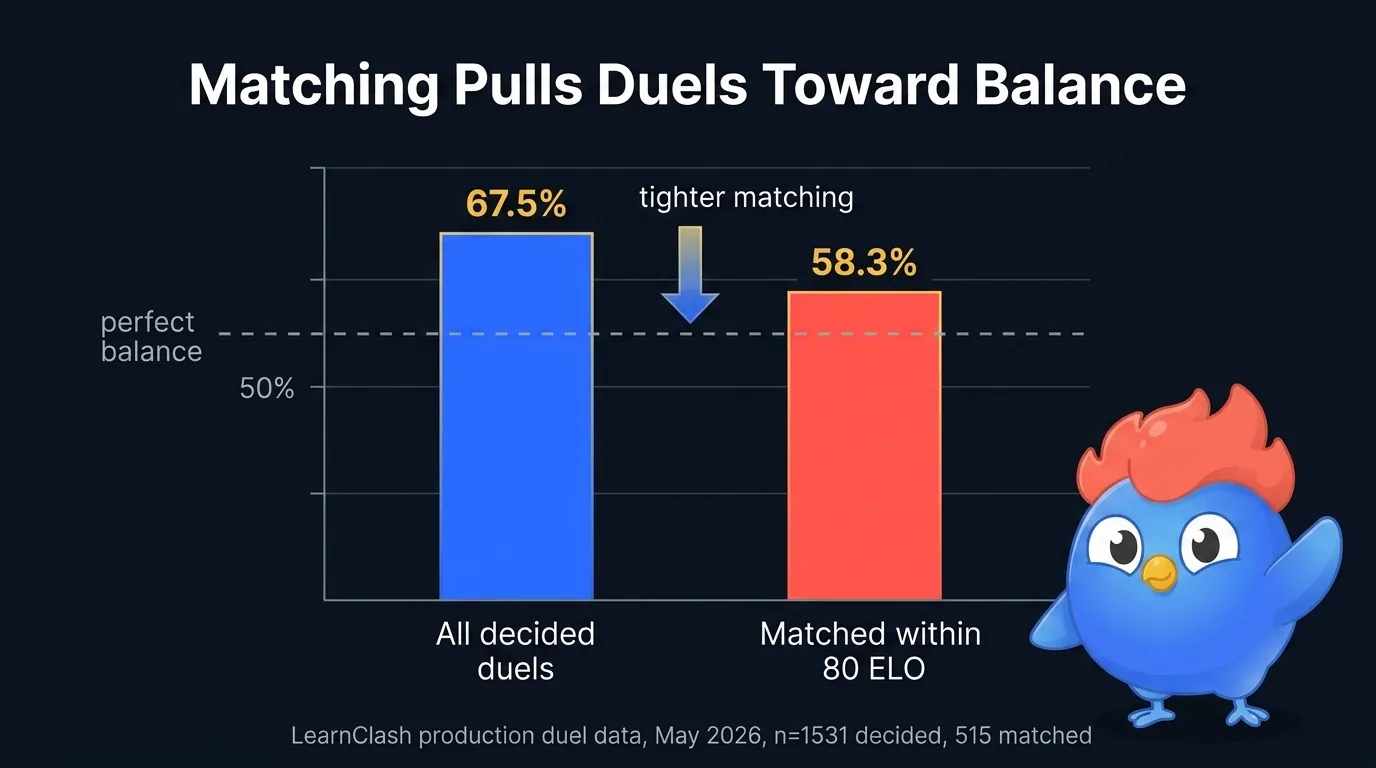 Figura 4: nuestros propios datos de producción. El jugador mejor puntuado gana el 67,5% de los duelos decididos en general, pero solo el 58,3% cuando los dos jugadores están dentro de 80 ELO. Un emparejamiento más ajustado acerca los resultados al equilibrio sin borrar la habilidad.
Figura 4: nuestros propios datos de producción. El jugador mejor puntuado gana el 67,5% de los duelos decididos en general, pero solo el 58,3% cuando los dos jugadores están dentro de 80 ELO. Un emparejamiento más ajustado acerca los resultados al equilibrio sin borrar la habilidad.
Lo medimos con nuestros propios datos. En el juego clasificado de LearnClash, el jugador mejor puntuado gana el 67,5 por ciento de los duelos decididos. En el subconjunto donde el emparejador unió a dos jugadores dentro de 80 ELO entre sí, el mejor puntuado gana solo el 58,3 por ciento, así que un emparejamiento ajustado acerca los resultados al equilibrio sin borrar la habilidad. Ese 58,3 por ciento es la franja de dificultad deseable que apunta el emparejador de LearnClash: más cerca que un emparejamiento aleatorio, pero todavía una pelea real. Fuente: datos de producción de duelos de LearnClash, exportados en mayo de 2026 (n = 1531 duelos decididos; 515 emparejados dentro de 80 ELO).
Las tres fuerzas:
- Calibración K-Factor 40: los primeros 10 duelos de un jugador nuevo oscilan amplios antes de asentarse
- Régimen K-Factor 20: los jugadores establecidos ven oscilaciones mucho más ajustadas alrededor de su puntuación real
- Desajustes profundos de tema: el compuesto puede dispararse con gran ELO y coseno mediocre
K-Factor 40 es la primera fuerza. Los nuevos jugadores de LearnClash empiezan en 1300 (Oro II, promedio del ladder). Un jugador nuevo puede moverse mucho en una sola sesión. Hasta que la calibración se ajusta, el emparejador tiene menos confianza en la puntuación, y los emparejamientos se ensanchan.
¿Sabías que…? Riot Games declaró en 2024 que un partido «justo» de League sitúa cada equipo dentro de ±1% del 50. La cifra es estándar de la industria, pero la razón por la que MOBAs y LearnClash convergen ahí difiere.
K-Factor 20 comprime todo. Una vez que un jugador tiene 10 duelos clasificados registrados, K baja a 20. La puntuación se mueve a la mitad de velocidad, así que cada duelo la empuja menos y la varianza de victoria se estrecha.
Los desajustes profundos de tema explican el resto. Una puntuación compuesta sobre el umbral de disparo puede superarse cuando el ELO es genial pero el coseno solo mediocre. El jugador cuyos temas recientes coinciden gana una pequeña ventaja que la diferencia de puntuación sola no puede predecir. Las plataformas de quiz de aula como Kahoot y Blooket no ofrecen ningún emparejamiento por habilidad, así que su brecha entre los de arriba y la media se mantiene mucho más amplia que la de un ladder emparejado por habilidad; nuestra comparación Kahoot vs Blooket cubre esa diferencia.
Punto clave: tres fuerzas explican las colas: calibración K=40, régimen K=20, y la pequeña pero real holgura de coseno de categoría que el compuesto permite.
Por qué el solapamiento de temas estrecha o ensancha la tasa
El solapamiento de temas es el segundo eje, y modula la franja más de lo que la mayoría de jugadores se da cuenta. En LearnClash, un coseno de categoría alto comprime la franja de tasa de victoria porque ambos jugadores comparten el mismo material; un coseno bajo deja que la familiaridad con el tema se cuele, así que incluso un duelo emparejado por ELO puede ensancharse. La familiaridad con el tema es habilidad oculta.
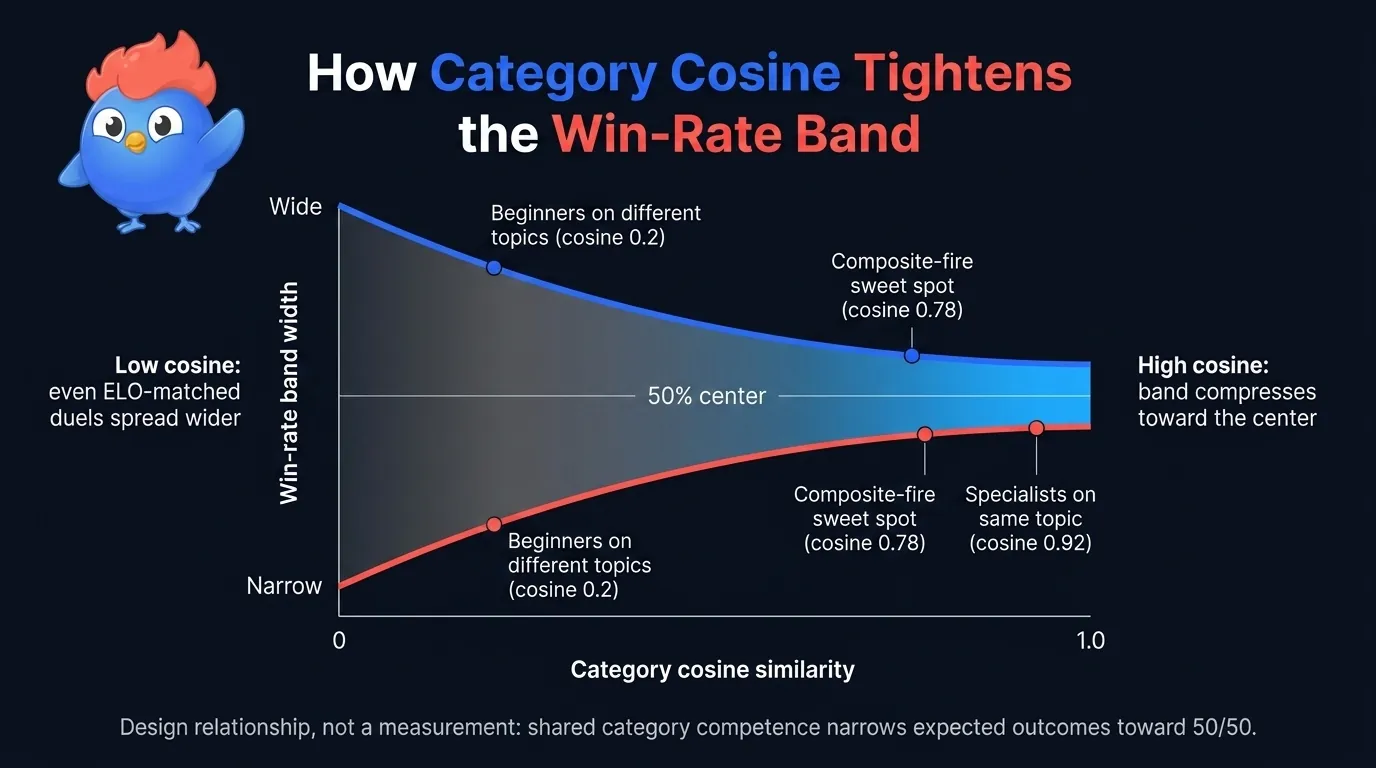 Figura 5: similitud de coseno de categoría frente a estrechez de la tasa. Un solapamiento alto comprime resultados; un solapamiento bajo deja que la familiaridad con el tema se cuele en el emparejamiento por puntuación sola.
Figura 5: similitud de coseno de categoría frente a estrechez de la tasa. Un solapamiento alto comprime resultados; un solapamiento bajo deja que la familiaridad con el tema se cuele en el emparejamiento por puntuación sola.
La intuición es simple.
Dos jugadores que pasaron el último mes en geografía europea llegan a un duelo de geografía europea con exposición similar. Habilidad, velocidad de recuerdo y lectura cuidadosa deciden el resultado. La franja sigue estrecha.
¿Sabías que…? Los emparejadores ELO puros en juegos MOBA fallan en un contexto de aprendizaje. La habilidad no es agnóstica al tema en un quiz: un jugador que ha respondido 500 preguntas de química tiene una ventaja enorme sobre uno que ha respondido 5, sin importar la puntuación.
Dos jugadores emparejados en biología molecular, donde solo uno ha jugado biología antes, ven la exposición superar a la habilidad cruda. El jugador familiar gana más a menudo de lo que ELO predeciría. Incluso con cero diferencia ELO, la franja se ensancha.
Punto clave: el puntuador compuesto es la solución. La familiaridad con el tema es habilidad oculta, y la capa de coseno la trata como tal.
El patrón es monótono: cuanto más alto el coseno de categoría, más estrecha la franja esperada, porque ambos jugadores beben de la misma exposición. A medida que el coseno baja, el jugador cuyos temas recientes coinciden gana una ventaja que la puntuación pura no puede ver, y la franja se ensancha incluso con cero diferencia ELO.
Cuando el emparejador tarda unos segundos extra, ese es el puntuador compuesto cazando una apertura con proximidad de habilidad y solapamiento de tema. Más fácil dicho que hecho en una cola pequeña. Pero esa pequeña espera es la diferencia entre un duelo que enseña y uno que frustra.
Punto clave: la proximidad ELO es necesaria pero no suficiente. La capa de coseno de categoría es lo que evita que la franja equilibrada se ensanche hacia un desajuste impulsado por el tema.
Cómo la calibración K-Factor dobla la curva
El K-Factor controla con cuánta agresividad el sistema actualiza una puntuación tras cada duelo. En LearnClash, tus primeros 10 duelos usan K=40 para calibración rápida. Después K baja a 20 para juego estable. La varianza de victoria cae con la bajada del K-Factor, y la franja se ajusta.
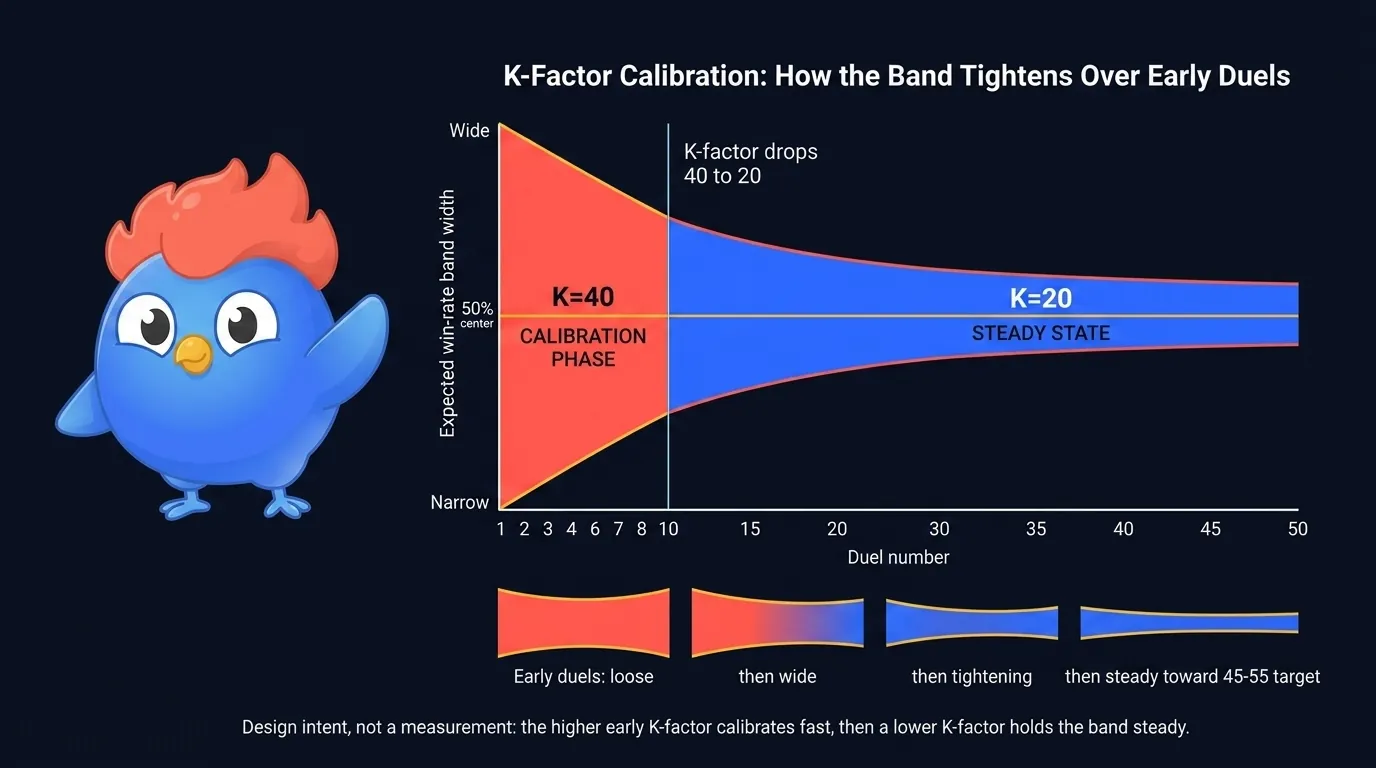 Figura 6: ajuste de calibración. K=40 produce oscilaciones tempranas amplias; el régimen K=20 mueve la puntuación a la mitad de velocidad y comprime la franja.
Figura 6: ajuste de calibración. K=40 produce oscilaciones tempranas amplias; el régimen K=20 mueve la puntuación a la mitad de velocidad y comprime la franja.
La matemática es básica. Doblar el K-Factor dobla el swing de puntuación por duelo.
¿Sabías que…? Bajo K=40, un solo duelo mueve una puntuación unas dos veces más lejos que bajo K=20, así que un mal tramo temprano en la calibración puede desplazar a un jugador nuevo unos cien puntos donde el mismo tramo más tarde lo movería solo la mitad.
Los amplios swings K=40 son intencionales. Dejan que la calibración encuentre tu habilidad real más rápido que la deriva gradual. A lo largo de los primeros 10 duelos la franja es holgada; una vez que K baja a 20 se ajusta, porque cada duelo ahora empuja menos la puntuación y el emparejador la lee con más confianza.
Cada nuevo jugador empieza en 1300 sin importar la habilidad real. Un jugador de élite tiene que subir. Un principiante tiene que caer. K=40 hace ambas cosas rápido, y los swings tempranos despejan el sesgo de la puntuación inicial compartida.
¿Sabías que…? La FIDE usa K=40/20 con la misma filosofía: calibración rápida, estabilidad lenta. Riot Games aterrizó cerca de los mismos números. El TrueSkill de Microsoft usaba un término bayesiano de incertidumbre que hace el mismo trabajo por un mecanismo distinto.
Después el sistema bloquea K en 20 y la puntuación apenas se mueve por duelo. El swing por duelo es lo bastante pequeño para que la volatilidad deje de pilotar la franja. La habilidad la pilota desde ese punto.
Así que cuando jugadores veteranos de LearnClash dicen «cada duelo se siente reñido ahora», eso no es nostalgia. El K-Factor literalmente comprime la varianza, y el emparejador lee la puntuación con más confianza. Combinado con el peso de solapamiento de tema del compuesto, la franja se ajusta hasta el punto en que la mayoría de los duelos terminan reñidos.
Cómo las victorias emparejadas por ELO amplifican la retención Mems de 3 etapas
Por esto el emparejamiento ELO es un sistema de memoria, no solo un sistema de engagement. En LearnClash, una victoria en un duelo emparejado por habilidad es una victoria ganada al borde del recuerdo, que es exactamente la condición que la literatura del aprendizaje dice que construye memoria duradera. Una victoria en un duelo desequilibrado no lo es. Esa diferencia es la razón de diseño por la que existe el emparejador compuesto.
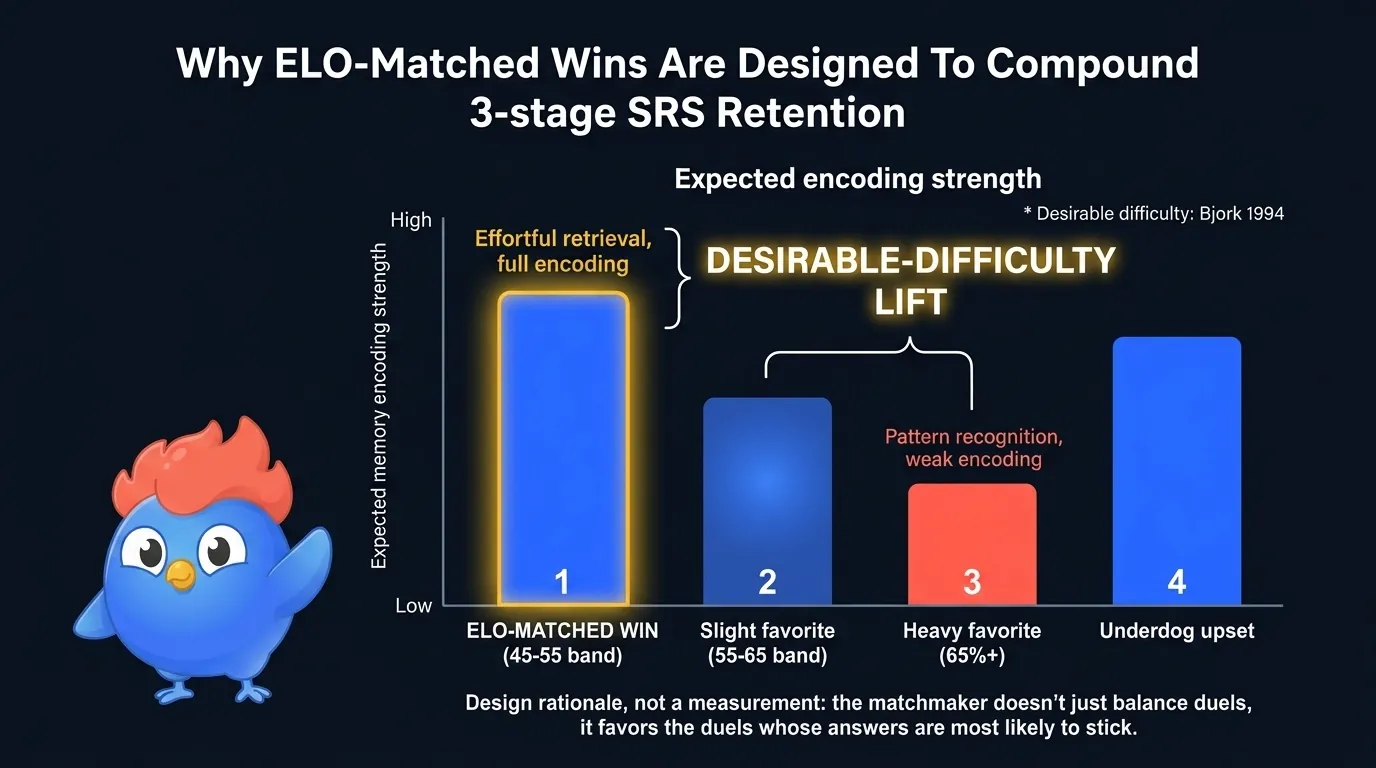 Figura 7: una victoria emparejada por habilidad se gana mediante recuerdo esforzado; una victoria aplastante se responde por reconocimiento de patrones. La primera es la zona de dificultad deseable donde la codificación es más fuerte.
Figura 7: una victoria emparejada por habilidad se gana mediante recuerdo esforzado; una victoria aplastante se responde por reconocimiento de patrones. La primera es la zona de dificultad deseable donde la codificación es más fuerte.
El mecanismo es el mismo principio de dificultad deseable que recorre este artículo, y tiene tres partes. Solo una es intuitiva.
- Activación: un duelo reñido eleva la activación y refuerza el encoding neural
- Dificultad de recuerdo: las preguntas que apenas aciertas se sitúan al borde del recuerdo, la zona Bjork
- Victorias aplastantes pobres en encoding: las victorias fáciles responden por reconocimiento de patrones, no recuerdo, así el cerebro apenas codifica
El primer impulsor es la activación. Un duelo reñido produce activación moderada y un encoding neural más fuerte, según el principio Yerkes-Dodson cubierto antes. Una pregunta correctamente respondida en ese estado codifica más duradero que la misma pregunta respondida en una ronda de práctica de bajo estrés. Salehi et al. (2019) demostraron el efecto activación-encoding en estudios de laboratorio.
El segundo impulsor es la dificultad de recuerdo. Las preguntas que apenas aciertas en un duelo equilibrado se sitúan al borde de tu capacidad de recuerdo, la zona que Bjork llamó dificultad deseable. El recuerdo que tiene éxito con esfuerzo deposita memoria más fuerte que el recuerdo que tiene éxito con facilidad.
«Las condiciones que ralentizan la tasa de adquisición a menudo producen la retención a largo plazo más duradera.» Robert Bjork, resumido en Making Things Hard on Yourself (2011)
El tercer impulsor es de lo que nadie habla. Las victorias aplastantes son pobres en encoding. Cuando un jugador domina, a menudo responde correctamente sin activar el recuerdo. La respuesta correcta llega por reconocimiento de patrones, por familiaridad de categoría, porque la pregunta es demasiado fácil. El cerebro apenas codifica esos momentos, y es más probable que un control SRS posterior detecte el hueco.
Por eso construimos el emparejador compuesto como lo construimos. No basta con querer duelos reñidos por engagement. Queremos duelos reñidos porque alimentan la curva de retención Mems de 3 etapas con recuerdos que sobreviven al control de 7 días, en lugar de victorias fáciles que se desvanecen. Los sistemas pensados para el atracón de una sola sesión o la energía de aula, como el modo Learn gratuito de Quizlet limitado a 5 rondas por set o el formato en vivo de Kahoot dirigido por host, no programan ese control en absoluto.
Punto clave: el emparejamiento ELO no es solo un sistema de engagement. En LearnClash es un sistema de calidad de memoria, porque una victoria difícil pero justa se gana en el límite del recuerdo donde la memoria se consolida.
Cómo LearnClash difiere de los MOBAs y TrueSkill
LearnClash hereda la fórmula ELO del ajedrez, la idea de desviación de puntuación de Glicko, y la idea de puntuación compuesta de nadie. En LearnClash, la puntuación pública sigue como ELO. El manejo de inactividad usa internamente crecimiento de desviación estilo Glicko. El emparejador superpone coseno de categoría.
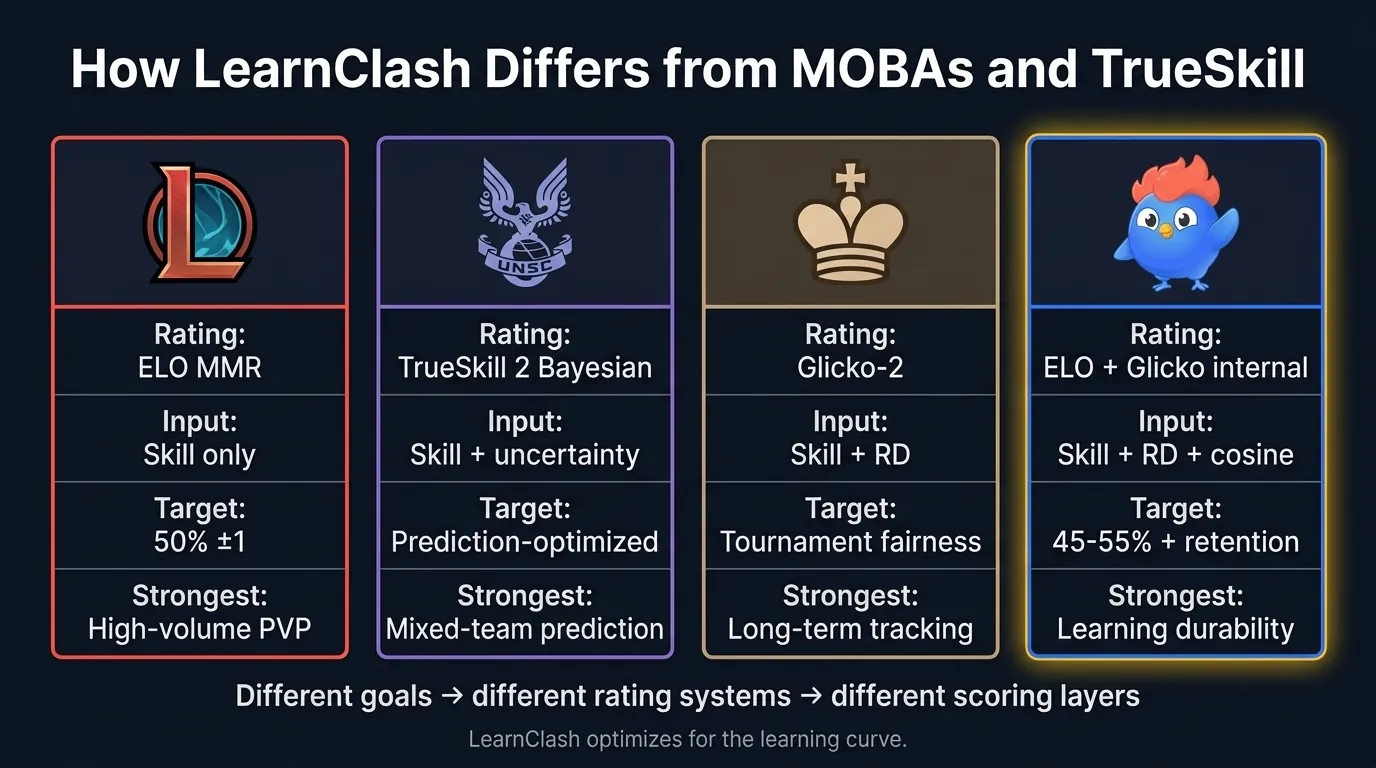 Figura 8: comparación de emparejadores entre League of Legends, Halo TrueSkill 2, Glicko-2 de ajedrez, y LearnClash. Diferentes metas, diferentes sistemas de puntuación, diferentes capas de scoring.
Figura 8: comparación de emparejadores entre League of Legends, Halo TrueSkill 2, Glicko-2 de ajedrez, y LearnClash. Diferentes metas, diferentes sistemas de puntuación, diferentes capas de scoring.
Los MOBAs resuelven un problema diferente y llegan a respuestas diferentes. La comparación de cuatro sistemas:
| League of Legends | Halo TrueSkill 2 | Ajedrez Glicko-2 | LearnClash | |
|---|---|---|---|---|
| Sistema de puntuación | ELO MMR | TrueSkill 2 bayesiano | Glicko-2 | ELO + Glicko interno |
| Entrada de emparejamiento | Solo habilidad | Habilidad + incertidumbre | Habilidad + RD | Habilidad + RD + coseno |
| Meta de victoria | 50% (política Riot) | Optimizado predicción | Justicia de torneo | Franja equilibrada + retención |
| Más fuerte en | PVP de alto volumen | Predicción de equipos mixtos | Seguimiento largo plazo | Durabilidad de aprendizaje |
| Debilidad | Ciego al tema | Cómputo pesado | Sin conciencia de categoría | Cola más estrecha a escala |
League of Legends usa un MMR interno distinto del rango visible. La meta declarada de Riot es que cada equipo tenga una expectativa de victoria del 50% ±1, lo que su equipo dev confirmó en 2024. La conspiración del 50% en los foros de League refleja una decisión real de diseño, aplicada al marco equivocado: los MOBAs apuntan a colas balanceadas, no a aprendizaje balanceado.
TrueSkill 2 de Microsoft (2018) es el más sofisticado matemáticamente. Trata la habilidad de cada jugador como una distribución de probabilidad y actualiza la varianza tras cada partida.
¿Sabías que…? TrueSkill 2 fue evaluado originalmente con datos de la beta de Halo 2. El sistema entrenó en cientos de millones de partidas antes de salir en Halo 5. Predice resultados con 68% de precisión, contra 52% del TrueSkill original.
El modelo maneja juego en equipo, empates y abandono nativamente. El coste es alta sobrecarga computacional y una puntuación pública que se mueve impredeciblemente para nuevos jugadores.
Glicko-2 de ajedrez (Mark Glickman, 1995, evolucionado 2001) añadió un término de desviación de puntuación a la media ELO. RD mide cuánta confianza tiene el sistema en tu puntuación ahora. Crece tras inactividad, encoge con juego regular, y deja que el sistema te empareje contra una franja más amplia cuando la incertidumbre es alta.
Punto clave: cada uno de los cuatro sistemas optimiza para una meta diferente. Los MOBAs optimizan para balance de cola. Microsoft optimiza para precisión predictiva. El ajedrez optimiza para justicia de torneo. LearnClash optimiza para la curva de aprendizaje.
El compuesto LearnClash escoge de cada uno. La puntuación pública se queda como ELO porque la familiaridad de marca y la legibilidad de niveles importan para la identidad del jugador. El crecimiento RD estilo Glicko corre debajo para capturar inactividad. La capa de coseno de categoría es la adición LearnClash y la razón por la que la franja se mantiene ajustada en lugar de ensancharse hacia desajustes impulsados por el tema.
Un duelo LearnClash y un partido clasificado de League comparten un ancestro y casi nada más. Diferentes metas. Diferentes matemáticas.
Veredicto final
El emparejamiento ELO deja los duelos LearnClash en una franja equilibrada de tasa de victoria, y esa franja es exactamente el punto. La queja del «50 forzado» que levantan los jugadores de MOBA es matemática real, pero el marco equivocado para un contexto de aprendizaje.
Punto clave: en LearnClash, una franja de victoria ajustada significa ganancias de retención ajustadas. Una victoria emparejada por habilidad se gana en el límite del recuerdo, la zona de dificultad deseable donde la tasa de aprobado del SRS a 7 días aguanta y una paliza fácil se desvanece.
Elige un tema. Tu primer duelo clasificado dura 3 minutos. El emparejador compuesto se encarga del resto. Lo que sentirás es la diferencia entre un quiz que deriva y un duelo que encaja exactamente en la ranura de tu habilidad donde la memoria se forma de verdad. Para la pieza hermana sobre el diseño detrás de por qué una ronda LearnClash Practice tiene 37 y no 50 preguntas, mira el impuesto de los números redondos en el diseño de quiz. Rétame en técnicas de estudio →.
Preguntas frecuentes
¿Qué es una tasa de victoria emparejada por ELO?
Una tasa de victoria emparejada por ELO es la probabilidad de ganar cuando ambos jugadores comparten una diferencia de puntuación estrecha. Cuando el emparejamiento elimina la diferencia de puntuación, ambos jugadores tienen probabilidades casi iguales, así que los resultados tienden a una franja equilibrada. Esa franja es lo que apunta el emparejamiento por habilidad, no una cuota forzada.
¿Está LearnClash forzando una tasa de victoria del 50%?
No. LearnClash empareja jugadores por habilidad, no manipulando los resultados. Los oponentes de habilidad pareja tienden de forma natural a una tasa de victoria equilibrada porque ambos tienen probabilidades casi iguales. La teoría del «50 forzado» en los foros MOBA confunde correlación con causalidad: un ELO equilibrado produce tasas equilibradas como consecuencia, no como objetivo.
¿Por qué LearnClash usa un compuesto 50/50 de proximidad ELO y solapamiento de categoría?
El emparejamiento ELO puro ignora la competencia por tema. Un jugador con historial de nivel Fénix en historia puede hundirse contra uno de nivel Fénix en física. El compuesto 50/50 de LearnClash pondera tanto habilidad como relevancia de tema, lo que mantiene los duelos aprendibles sin un filtro duro de puntuación.
¿Cómo se compara el emparejamiento ELO con TrueSkill o Glicko-2?
TrueSkill 2 (Microsoft, 2018) rastrea la incertidumbre de habilidad junto con la media y predice resultados con 68% de precisión. Glicko añade desviación de puntuación que crece con la inactividad. LearnClash usa Glicko internamente para inactividad pero mantiene la puntuación pública como ELO y añade coseno de categoría, porque el valor de aprendizaje depende de la coincidencia de tema, no solo de habilidad.
¿Mejora la retención de memoria ganar más a menudo en duelos emparejados por ELO?
Los duelos emparejados por habilidad se sitúan en la zona de dificultad deseable de Bjork, donde el recuerdo tiene éxito con esfuerzo. Ese esfuerzo es lo que convierte una respuesta correcta en memoria duradera, así que una victoria difícil pero justa codifica más fuerte que una paliza fácil. El SRS de 3 etapas programa luego la revisión que la fija.