ELO-Matchmaking und Siegquoten: Kompetenz gewinnt [2026]
ELO-Matchmaking paart LearnClash-Duelle nach Kompetenz, sodass jedes nah an der Zone wünschenswerter Schwierigkeit landet, wo Abruf zu Gedächtnis wird.


Kompetenz-gematchte ELO-Duelle in LearnClash tendieren zu einer ausgeglichenen Siegquote. Zufallspaarung tut das nicht. Nicht annähernd.
Eine ELO-gematchte Siegquote ist die Gewinnwahrscheinlichkeit, wenn beide Spieler einen engen Bewertungsabstand teilen. In LearnClash bewertet der Composite-Matchmaker offene Duelle mit 50 Prozent ELO-Nähe plus 50 Prozent Kategorien-Cosinus-Ähnlichkeit, gleichgewichtet, ohne harten Bewertungsbereich-Filter, und die entstehende Balance ist die Zone wünschenswerter Schwierigkeit, die Lernforschung seit über 30 Jahren benannt hat.
Unten: die Mathematik hinter dem ausgeglichenen Band, warum „erzwungene 50“ der falsche Rahmen ist, wie K-Faktor-Kalibrierung und Themenüberschneidung Paarungen formen, und wie ein enges Kompetenz-Match die 3-stufige SRS-Retention verstärkt. Probiere ein 3-minütiges LearnClash-Duell und sieh es selbst.
Was ist eine ELO-gematchte Siegquote?
Eine ELO-gematchte Siegquote ist der Prozentsatz an Duellen, die du gegen einen kompetenzgleichen Gegner gewinnen kannst. In LearnClash clustert dieser Wert um 50 Prozent, weil der Matchmaker den Bewertungsabstand entfernt, der ihn höher oder niedriger drücken würde.
 Abbildung 1: Ein ELO-gematchtes Duell sitzt per Definition bei 50 % Gewinnwahrscheinlichkeit. Füge eine 400-Punkte-Lücke hinzu und die Mathematik kollabiert auf 9 % für den niedriger bewerteten Spieler.
Abbildung 1: Ein ELO-gematchtes Duell sitzt per Definition bei 50 % Gewinnwahrscheinlichkeit. Füge eine 400-Punkte-Lücke hinzu und die Mathematik kollabiert auf 9 % für den niedriger bewerteten Spieler.
Aber hier wird’s interessant.
Die Erwartungswert-Formel, die Arpad Elo 1960 veröffentlichte, ist denkbar einfach. Die Gewinnwahrscheinlichkeit jedes Spielers ergibt sich aus dem Bewertungsabstand, nicht aus einem externen Regler. Keine Quoten. Keine versteckte Hand. Keine unsichtbare Steuer auf eine Siegesserie.
Wichtigste Erkenntnis: Das 50-Prozent-Band, das du siehst, ist die Mathematik, nicht die Anweisung. Zwei gleiche Bewertungen geben 0,5 für beide. Eine 400-Punkte-Lücke schiebt den stärkeren Spieler auf 0,91 und den schwächeren auf 0,09.
| Szenario | Spieler A ELO | Spieler B ELO | A’s Erwartungswert |
|---|---|---|---|
| Gleichstand | 1.300 | 1.300 | 50 % |
| Leichter Favorit | 1.400 | 1.300 | 64 % |
| Schwerer Favorit | 1.700 | 1.300 | 91 % |
| Außenseiter | 1.300 | 1.700 | 9 % |
„Eine Spielerbewertung ist eine Zahl, die als Index der Leistungsfähigkeit verwendet werden kann. Ihr Zweck ist, eine faire Methode der Handicap-Vergabe bereitzustellen.“ Arpad Elo, The Rating of Chessplayers, Past and Present (1978)
LearnClash erbt die Mathematik hinter ELO und legt einen Composite-Matchmaker darüber. Der Composite bewertet offene Duelle auf zwei Achsen gleichzeitig. Kompetenz-Nähe. Themenrelevanz. Die Paarung minimiert sowohl Bewertungsabstand als auch Kategoriendrift, sodass das Siegquoten-Band eng bleibt, selbst wenn das Thema zwischen Runden wechselt.
Wusstest du? Pelanek (2016) validierte ELO-Stil-Matchmaker für adaptive Bildung. Duolingo übernahm intern ein Pelanek-Stil-System und meldete einen 12-prozentigen Anstieg der täglichen Aktivität.
Ein ausgeglichenes Duell ist der Motor. Ein einseitiges Duell ist eine Kalibrierungsphase oder ein Themenüberschneidungs-Rand. Der Rest dieses Artikels packt aus, warum sich das eine großartig anfühlt und das andere kaputt, und warum das ausgeglichene Band, über das MOBA-Spieler klagen, dasselbe Band ist, das jedes gut entworfene Lernspiel absichtlich will.
Warum ein ausgeglichenes Band das Feature ist, kein Bug
Ein ausgeglichenes Siegquoten-Band ist das natürliche Ergebnis kompetenz-gematchten Wettbewerbs. In LearnClash ist dieses Band die Zone wünschenswerter Schwierigkeit, in der Abruf zu dauerhaftem Gedächtnis wird. Leichte Siege lehren fast nichts. Klare Niederlagen lehren weniger. Die Mitte ist, wo das Gehirn arbeitet.
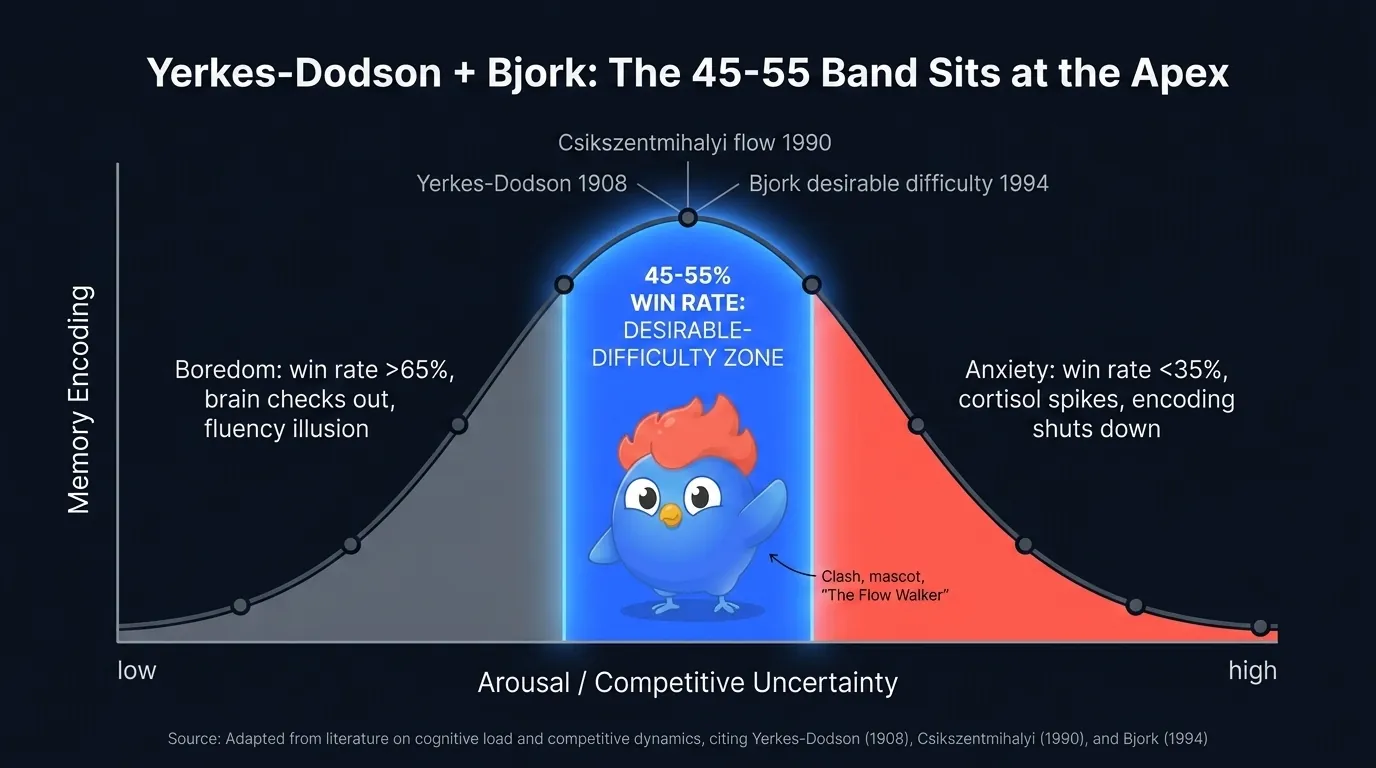 Abbildung 2: Die Yerkes-Dodson-Kurve mappt Erregung auf Lernleistung. ELO-gematchte Duelle sitzen am Scheitelpunkt; klare Niederlagen in beide Richtungen kollabieren den Encoding-Lift.
Abbildung 2: Die Yerkes-Dodson-Kurve mappt Erregung auf Lernleistung. ELO-gematchte Duelle sitzen am Scheitelpunkt; klare Niederlagen in beide Richtungen kollabieren den Encoding-Lift.
Durchsuche jedes deutschsprachige MOBA-Forum. Du findest dieselbe Verschwörungstheorie überall:
- Riot erzwingt 50 Prozent
- Dota 2 deckelt dich
- Apex Legends drosselt deine Siege
Die Klage ist älter als kompetenzbasiertes Matchmaking. Sie taucht in jedem Riot-Dev-Blog seit einem Jahrzehnt auf.
Aber an der Klage stimmt was nicht.
Wichtigste Erkenntnis: Eine faire Paarung produziert ein faires Ergebnis. Zwei gleichstarke Spieler können nicht anders, als über hunderte Spiele auf 50 Prozent zu tendieren. Das System hat die Siegquote nicht gewählt. Die Kompetenzen haben es.
Im Lernkontext kippt das von verdächtig zu optimal. Drei Stränge der Kognitionswissenschaft konvergieren auf das ausgeglichene Band als Optimum:
- Yerkes-Dodson-Gesetz (1908): moderate Erregung erzeugt Spitzen-Gedächtnis-Encoding
- Csikszentmihalyi Flow (1990): Herausforderung-Kompetenz-Balance triggert vertiefte Aufmerksamkeit
- Bjork wünschenswerte Schwierigkeit (1994): Abruf, der knapp gelingt, festigt Gedächtnisspuren
„Bedingungen, die während des Lernens langsamere oder fehlerhaftere Leistung erzeugen, führen oft zu besserer Langzeitretention.“ Elizabeth und Robert Bjork, Making Things Hard on Yourself (2011)
Das Yerkes-Dodson umgekehrte U ist das älteste der drei. Zu wenig Erregung, du schaltest ab. Zu viel, du verkrampfst. In einem Duell kommt diese Erregung aus Wettkampfunsicherheit. Eine klare Niederlage in eine Richtung kollabiert auf eine flache Linie. Ein 50-50-Kampf bleibt bis zur letzten Frage spannend.
 Abbildung 2b: Die Flüssigkeitsillusion. Leichte Siege fühlen sich nach Beherrschung an, aber das Gehirn encodiert die Antwort kaum. Die ausgeglichene Abruf-Grenze ist, wo Gedächtnisspuren tatsächlich entstehen.
Abbildung 2b: Die Flüssigkeitsillusion. Leichte Siege fühlen sich nach Beherrschung an, aber das Gehirn encodiert die Antwort kaum. Die ausgeglichene Abruf-Grenze ist, wo Gedächtnisspuren tatsächlich entstehen.
Csikszentmihalyis Flow-Kanal mappt dieselbe Form auf Aufmerksamkeit. Flow entsteht nur, wenn die wahrgenommene Herausforderung am Rand der wahrgenommenen Kompetenz sitzt. Unter dem Rand: Langeweile. Über dem Rand: Angst. Der Sweetspot ist schmal, und ELO-Matchmaking ist der Algorithmus, der ihn findet.
MOBA-Spieler haben also recht, dass das System Siegquoten Richtung 50 schiebt. Sie haben unrecht, dass das ein Problem ist. In LearnClash ist das genau der Punkt. Wir wollen, dass jedes Duell in der Zone landet, wo dein Gehirn die Antwort encodiert, nicht in der Zone, wo du cruist oder panikst.
Wie bewertet LearnClashs Composite-Matchmaker ein Duell?
In LearnClash bewertet der Composite-Matchmaker jedes offene Duell mit einer 50/50-gewichteten Mischung. ELO-Nähe misst, wie nahe zwei Bewertungen liegen. Kategorien-Cosinus-Ähnlichkeit misst Themenüberschneidung. Der kombinierte Score entscheidet, ob eine Paarung zündet oder in der Warteschlange bleibt.
 Abbildung 3: Der Composite-Bewerter belohnt sowohl Kompetenz-Nähe als auch Themenrelevanz. Eine 40-Punkte-ELO-Lücke mit starker Themenüberschneidung zündet; eine 40-Punkte-Lücke ohne Überschneidung wartet in der Warteschlange.
Abbildung 3: Der Composite-Bewerter belohnt sowohl Kompetenz-Nähe als auch Themenrelevanz. Eine 40-Punkte-ELO-Lücke mit starker Themenüberschneidung zündet; eine 40-Punkte-Lücke ohne Überschneidung wartet in der Warteschlange.
Die Kompetenz-Achse ist geradlinig.
ELO-Nähe scort 1,0 bei null Bewertungsabstand. Sie zerfällt glatt auf 0 bei einer 400-Punkte-Lücke.
Wusstest du? Eine 40-Punkte-Lücke gibt 0,96 auf der Nähe-Kurve. Eine 100-Punkte-Lücke gibt 0,86. Eine 200-Punkte-Lücke fällt auf 0,5.
Die Relevanz-Achse ist, was die meisten Matchmaker überspringen. Kategorien-Cosinus-Ähnlichkeit behandelt jeden Spielers jüngste Themen-Historie als Vektor. Cosinus gibt 1,0 zurück, wenn beide dieselben Kategorien gespielt haben. Sie gibt 0 zurück, wenn sie nichts teilen.
| Lücke | ELO-Nähe | Kommentar |
|---|---|---|
| 0 | 1,0 | Gleiche Bewertung |
| 40 | 0,96 | Composite zündet leicht |
| 100 | 0,86 | Composite zündet mit Themenmatch |
| 200 | 0,50 | Composite braucht starkes Themenmatch |
| 400 | 0,00 | Composite blockiert die Paarung |
Arbeitsbeispiel:
| Spieler A (1.340 ELO) | Spieler B (1.380 ELO) | |
|---|---|---|
| Letzte Themen | Europa, Geographie, klassische Musik | Europa, Geographie, Weltkino |
| ELO-Lücke | k. A. | 40 Punkte |
| ELO-Nähe | k. A. | 0,96 |
| Kategorien-Cosinus | k. A. | 0,83 |
| Composite-Score | k. A. | 0,90 |
| Match zündet? | k. A. | Ja (über 0,85) |
Die duale Bedingung ist, was das Band verengt: eine Paarung muss eng in der Bewertung und im Thema ausgerichtet sein, bevor der Composite die Zünd-Schwelle überschreitet, sodass die meisten zündenden Duelle sowohl kompetenz-ausgeglichen als auch themenrelevant sind.
Der Composite ist absichtlich gleichgewichtet. Reines ELO-Matchmaking ignoriert Themenkompetenz. Ein Phönix-Geschichtsspezialist würde einen Phönix-Physik-Spezialisten in der falschen Kategorie zerlegen. Reines Themenmatching ignoriert Kompetenz-Kalibrierung. Zwei Anfänger mit identischen Themeninteressen würden nie Lernfortschritte sehen.
Wichtigste Erkenntnis: Ein Composite-Matchmaker belohnt sowohl Kompetenz als auch Themenmatch. Ohne Kategorien-Cosinus kann ELO-Matching allein kein lernbares Duell garantieren.
Was ein Duell aus dem ausgeglichenen Band drängt
Ein kompetenz-gematchtes LearnClash-Duell tendiert zu einem ausgeglichenen Siegerwartungswert, aber drei Kräfte drängen einzelne Duelle in die Schwänze. Jede ist eine Eigenschaft des Systems, kein Bug.
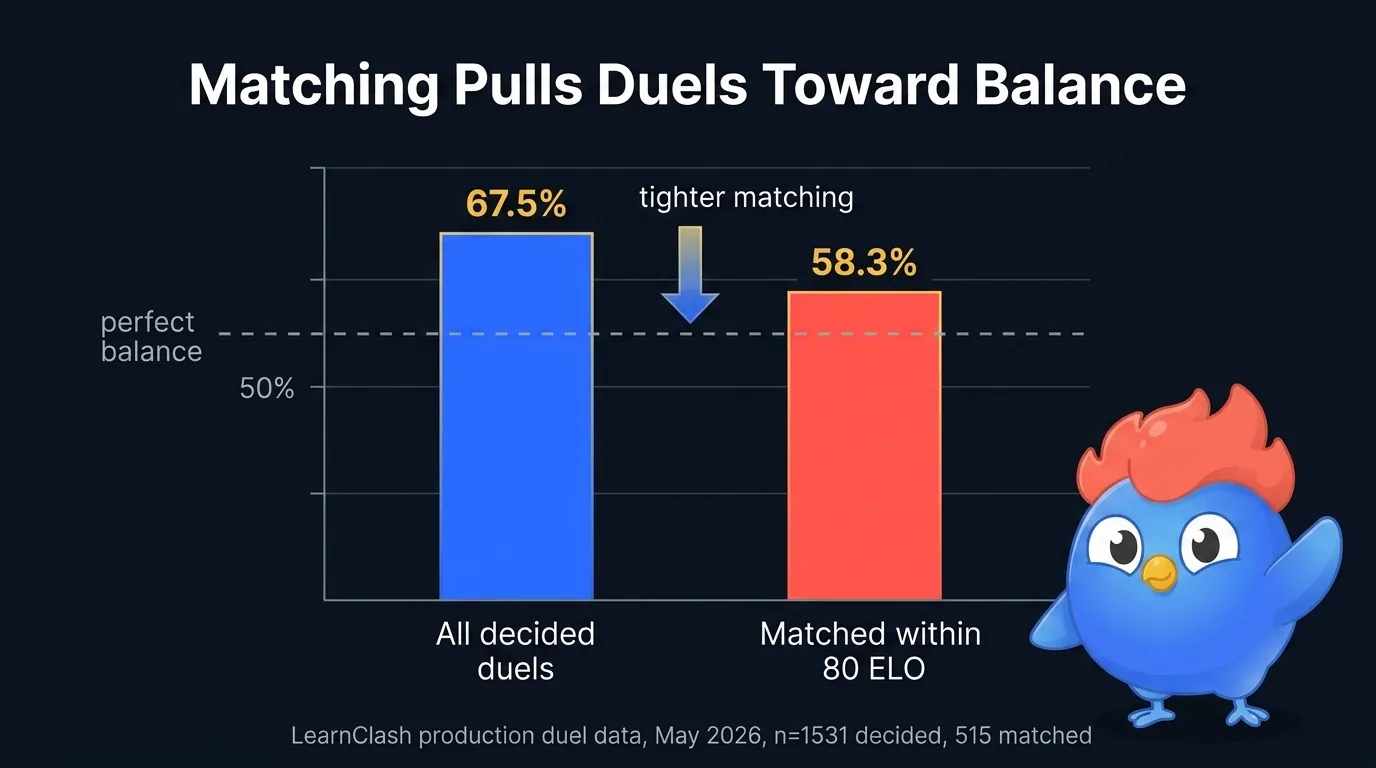 Abbildung 4: Unsere eigenen Produktions-Dueldaten. Der höher bewertete Spieler gewinnt 67,5 % der entschiedenen Duelle insgesamt, aber nur 58,3 %, wenn die beiden Spieler innerhalb von 80 ELO liegen. Engeres Matching zieht Ergebnisse Richtung Balance, ohne Kompetenz auszulöschen.
Abbildung 4: Unsere eigenen Produktions-Dueldaten. Der höher bewertete Spieler gewinnt 67,5 % der entschiedenen Duelle insgesamt, aber nur 58,3 %, wenn die beiden Spieler innerhalb von 80 ELO liegen. Engeres Matching zieht Ergebnisse Richtung Balance, ohne Kompetenz auszulöschen.
Wir haben das in unseren eigenen Daten gemessen. Über den LearnClash-Ranglistenbetrieb gewinnt der höher bewertete Spieler 67,5 Prozent der entschiedenen Duelle. In der Teilmenge, in der der Matchmaker zwei Spieler innerhalb von 80 ELO voneinander paarte, gewinnt der höher bewertete Spieler nur 58,3 Prozent, enges Matching zieht die Ergebnisse also Richtung Balance, ohne Kompetenz auszulöschen. Diese 58,3 Prozent sind das Band wünschenswerter Schwierigkeit, das der LearnClash-Matchmaker anvisiert: enger als Zufallspaarung, aber immer noch ein echter Wettkampf. Quelle: LearnClash-Produktions-Dueldaten, exportiert Mai 2026 (n = 1.531 entschiedene Duelle; 515 innerhalb von 80 ELO gematcht).
Die drei Kräfte:
- K-Faktor 40 Kalibrierung: die ersten 10 Duelle eines neuen Spielers schwingen weit, bevor sie sich setzen
- K-Faktor 20 Steady-State: etablierte Spieler sehen weit engere Schwankungen um ihre wahre Bewertung
- Tiefe Themen-Mismatches: der Composite kann bei großartigem ELO mit mittelmäßigem Cosinus zünden
K-Faktor 40 ist die erste Kraft. Neue LearnClash-Spieler starten bei 1.300 (Gold II, Leiter-Durchschnitt). Ein neuer Spieler kann sich in einer Sitzung weit bewegen. Bis die Kalibrierung greift, hat der Matchmaker weniger Vertrauen in die Bewertung, und Paarungen werden weiter.
Wusstest du? Riot Games erklärte 2024, dass ein „faires“ League-Match jedes Team innerhalb ±1 Prozent von 50 hat. Die Zahl ist Industriestandard, aber der Grund, warum MOBAs und LearnClash darauf konvergieren, unterscheidet sich.
K-Faktor 20 komprimiert alles. Sobald ein Spieler 10 Ranglisten-Duelle abgeschlossen hat, sinkt K auf 20. Die Bewertung bewegt sich halb so schnell, also stößt jedes Duell sie weniger an und die Siegquoten-Varianz zieht sich enger zusammen.
Tiefe Themen-Mismatches erklären den Rest. Ein Composite-Score über der Zünd-Schwelle kann durchgehen, wenn ELO großartig ist, aber der Cosinus nur mittelmäßig. Der Spieler, dessen letzte Themen passen, bekommt einen kleinen Vorteil, den der Bewertungsabstand allein nicht vorhersagen kann. Klassenraum-Quiz-Plattformen wie Kahoot und Blooket bieten überhaupt kein skill-basiertes Matching, sodass ihre Top-vs-Median-Lücke weit breiter bleibt als die einer kompetenz-gematchten Leiter; unser Kahoot vs Blooket Vergleich behandelt diesen Unterschied.
Wichtigste Erkenntnis: Drei Kräfte erklären die Schwänze: K=40 Kalibrierung, K=20 Steady-State und der kleine, aber reale Kategorien-Cosinus-Spielraum, den der Composite zulässt.
Warum Themenüberschneidung das Band verengt oder weitet
Themenüberschneidung ist die zweite Achse, und sie moduliert das Band stärker, als die meisten Spieler realisieren. In LearnClash komprimiert ein hoher Kategorien-Cosinus das Siegquoten-Band, weil beide Spieler dasselbe Material teilen; ein niedriger Cosinus lässt Themenvertrautheit durchsickern, sodass selbst ein ELO-gematchtes Duell spreizen kann. Themenvertrautheit ist verborgene Kompetenz.
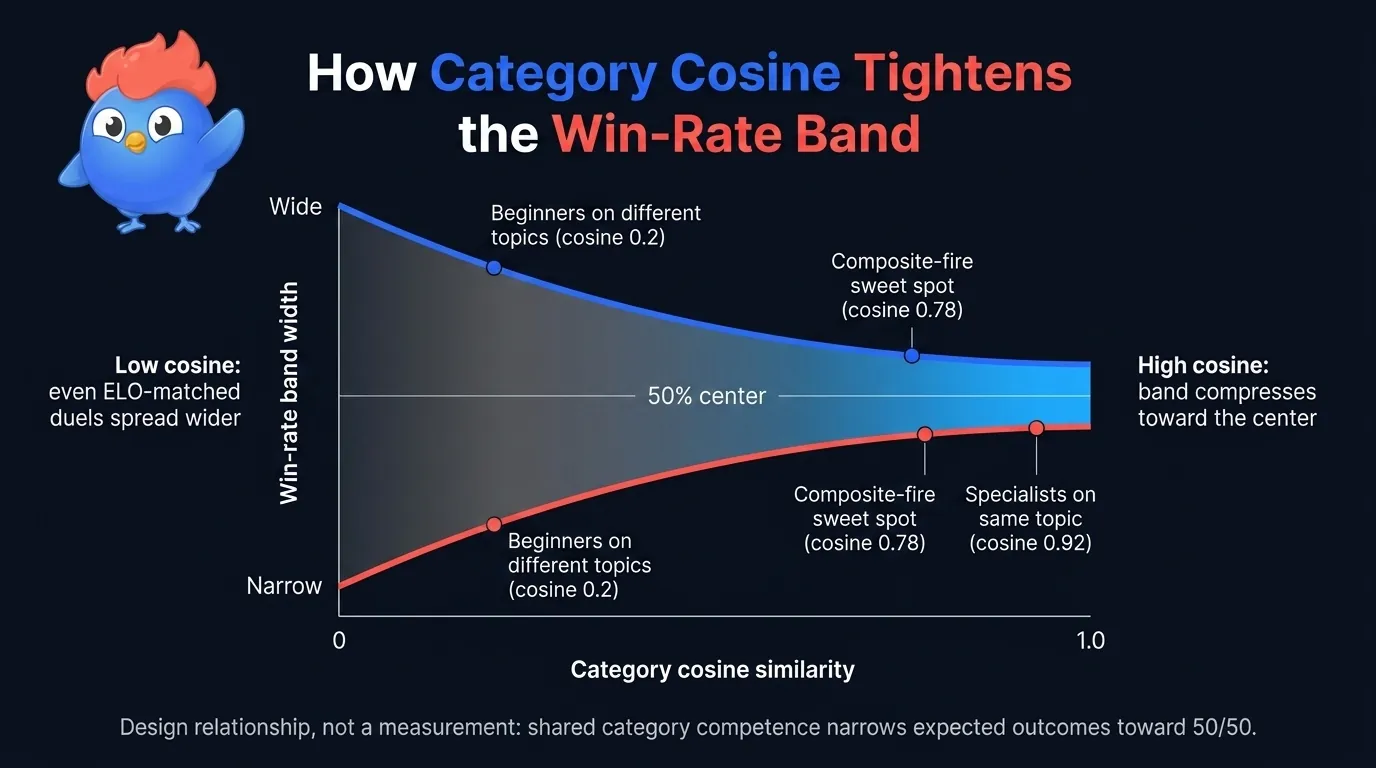 Abbildung 5: Kategorien-Cosinus-Ähnlichkeit gegen Siegquoten-Band-Enge. Hohe Überschneidung komprimiert Ergebnisse; niedrige Überschneidung lässt Themenvertrautheit ins reine Bewertungs-Matching durchsickern.
Abbildung 5: Kategorien-Cosinus-Ähnlichkeit gegen Siegquoten-Band-Enge. Hohe Überschneidung komprimiert Ergebnisse; niedrige Überschneidung lässt Themenvertrautheit ins reine Bewertungs-Matching durchsickern.
Und die Intuition ist einfach.
Zwei Spieler, die den letzten Monat mit europäischer Geographie verbracht haben, kommen zu einem Europa-Geographie-Duell mit ähnlicher Exposition. Kompetenz, Abruftempo und sorgfältiges Lesen entscheiden den Ausgang. Das Siegquoten-Band bleibt schmal.
Wusstest du? Reine ELO-Matchmaker in MOBA-Spielen scheitern im Lernkontext. Kompetenz ist in einem Quiz nicht themenagnostisch: ein Spieler, der 500 Chemiefragen beantwortet hat, hat einen riesigen Vorteil gegenüber einem, der 5 beantwortet hat, unabhängig von der Bewertung.
Zwei Spieler, die auf Molekularbiologie gematcht werden, wo nur einer vorher Biologie gespielt hat, sehen Exposition Kompetenz überwiegen. Der vertraute Spieler gewinnt häufiger, als ELO vorhersagen würde. Selbst bei null ELO-Lücke spreizt die Siegquote.
Wichtigste Erkenntnis: Der Composite-Bewerter ist die Lösung. Themenvertrautheit ist verborgene Kompetenz, und die Cosinus-Schicht behandelt sie als solche.
Das Muster ist monoton: je höher der Kategorien-Cosinus, desto enger das erwartete Band, weil beide Spieler aus derselben Exposition schöpfen. Sinkt der Cosinus, gewinnt der Spieler, dessen letzte Themen passen, einen Vorteil, den reine Bewertung nicht sehen kann, und das Band weitet sich selbst bei null ELO-Lücke.
Wenn der Matchmaker ein paar Sekunden länger braucht, ist das der Composite-Bewerter, der einen Eröffner mit Kompetenz-Nähe und Themenüberschneidung jagt. Leichter gesagt als getan in einer kleinen Warteschlange. Aber dieser kleine Aufschub ist der Unterschied zwischen einem Duell, das lehrt, und einem, das frustriert.
Wichtigste Erkenntnis: ELO-Nähe ist notwendig, aber nicht ausreichend. Die Kategorien-Cosinus-Schicht ist, was das ausgeglichene Band davor bewahrt, sich in ein themen-getriebenes Mismatch zu weiten.
Wie die K-Faktor-Kalibrierung die Kurve biegt
Der K-Faktor steuert, wie aggressiv das System eine Bewertung nach jedem Duell aktualisiert. In LearnClash nutzen deine ersten 10 Duelle K=40 für schnelle Kalibrierung. Dann fällt K auf 20 für stabilen Spielbetrieb. Die Siegquoten-Varianz fällt mit dem K-Faktor-Drop, und das Band zieht sich enger.
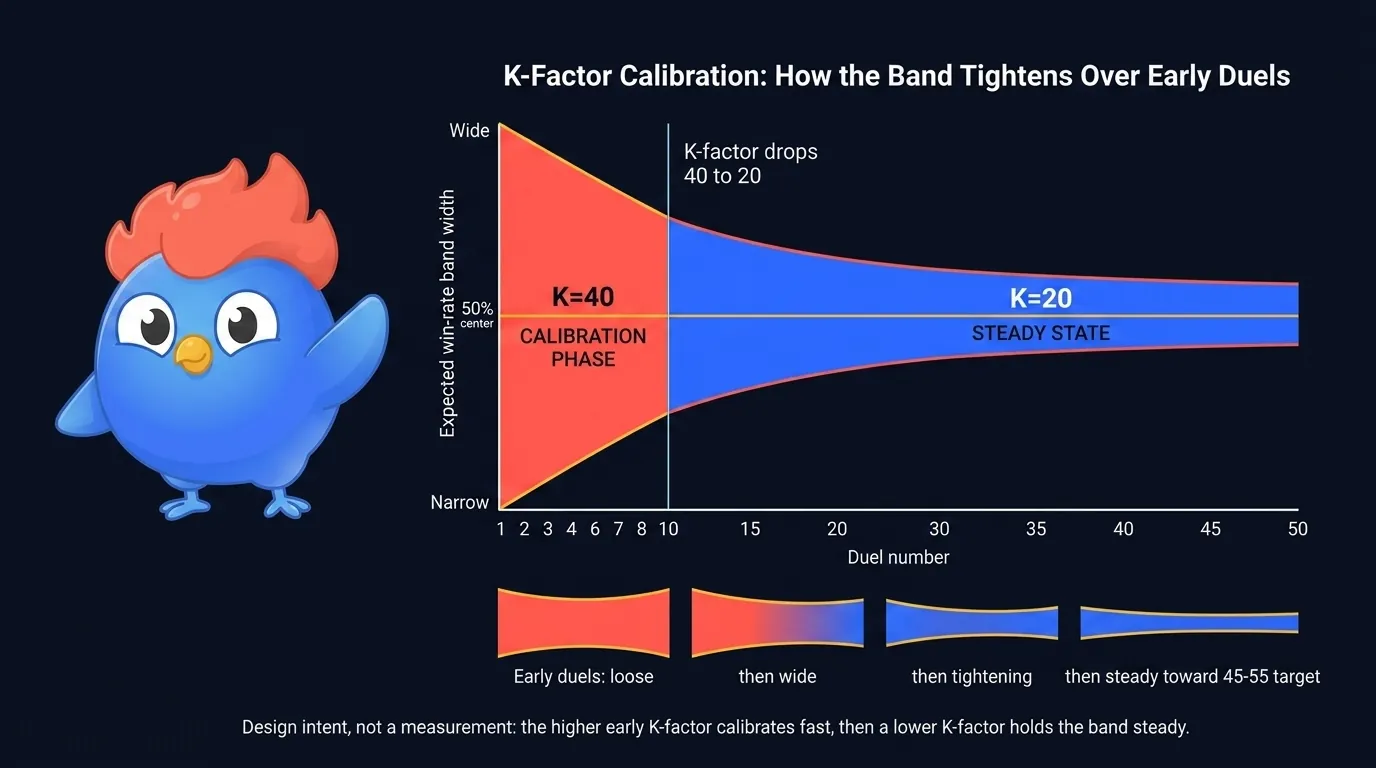 Abbildung 6: Kalibrierungs-Verengung. K=40 produziert weite frühe Schwünge; der K=20-Steady-State bewegt die Bewertung mit halber Geschwindigkeit und komprimiert das Band.
Abbildung 6: Kalibrierungs-Verengung. K=40 produziert weite frühe Schwünge; der K=20-Steady-State bewegt die Bewertung mit halber Geschwindigkeit und komprimiert das Band.
Die Mathematik ist simpel. Verdopplung des K-Faktors verdoppelt den Bewertungs-Schwung pro Duell.
Wusstest du? Unter K=40 bewegt ein einzelnes Duell eine Bewertung etwa doppelt so weit wie unter K=20, sodass eine schwache Phase früh in der Kalibrierung einen neuen Spieler um rund hundert Punkte verschieben kann, wo derselbe Lauf später nur die Hälfte davon verschöbe.
Die breiten K=40-Schwünge sind beabsichtigt. Sie lassen Kalibrierung deine echte Kompetenz schneller finden, als allmähliche Drift es täte. Über die ersten 10 Duelle ist das Band lose; sobald K auf 20 fällt, zieht es sich enger, weil jedes Duell die Bewertung jetzt weniger anstößt und der Matchmaker sie mit mehr Vertrauen liest.
Jeder neue Spieler beginnt bei 1.300, unabhängig von echter Kompetenz. Ein Spitzenspieler muss klettern. Ein Anfänger muss fallen. K=40 macht beides schnell, und die frühen Schwünge schälen den geteilten Startbewertungs-Bias ab.
Wusstest du? FIDE nutzt K=40/20 mit derselben Philosophie: schnelle Kalibrierung, langsame Stabilität. Riot Games landete bei nahen Zahlen. Microsofts TrueSkill nutzte einen Bayesschen Unsicherheitsterm, der dieselbe Arbeit durch einen anderen Mechanismus erledigt.
Dann sperrt das System K bei 20, und die Bewertung bewegt sich pro Duell kaum. Der Schwung pro Duell ist klein genug, dass Volatilität aufhört, das Band zu treiben. Kompetenz treibt es ab diesem Punkt.
Wenn Veteranen-LearnClash-Spieler sagen „jetzt fühlt sich jedes Duell eng an“, ist das keine Nostalgie. Der K-Faktor komprimiert die Varianz buchstäblich, und der Matchmaker liest die Bewertung mit mehr Vertrauen. Kombiniert mit dem Themenüberschneidungs-Gewicht des Composite-Bewerters zieht sich das Band so eng, dass die meisten Duelle knapp enden.
Wie ELO-gematchte Siege die 3-stufige SRS-Retention verstärken
Deshalb ist ELO-Matching ein Gedächtnissystem, nicht nur ein Engagement-System. In LearnClash ist ein Sieg in einem kompetenz-gematchten Duell ein Sieg, der am Rand des Abrufs verdient wird, genau die Bedingung, von der die Lernliteratur sagt, dass sie dauerhaftes Gedächtnis aufbaut. Ein Sieg in einem einseitigen Duell ist das nicht. Dieser Unterschied ist der Design-Grund, warum der Composite-Matchmaker existiert.
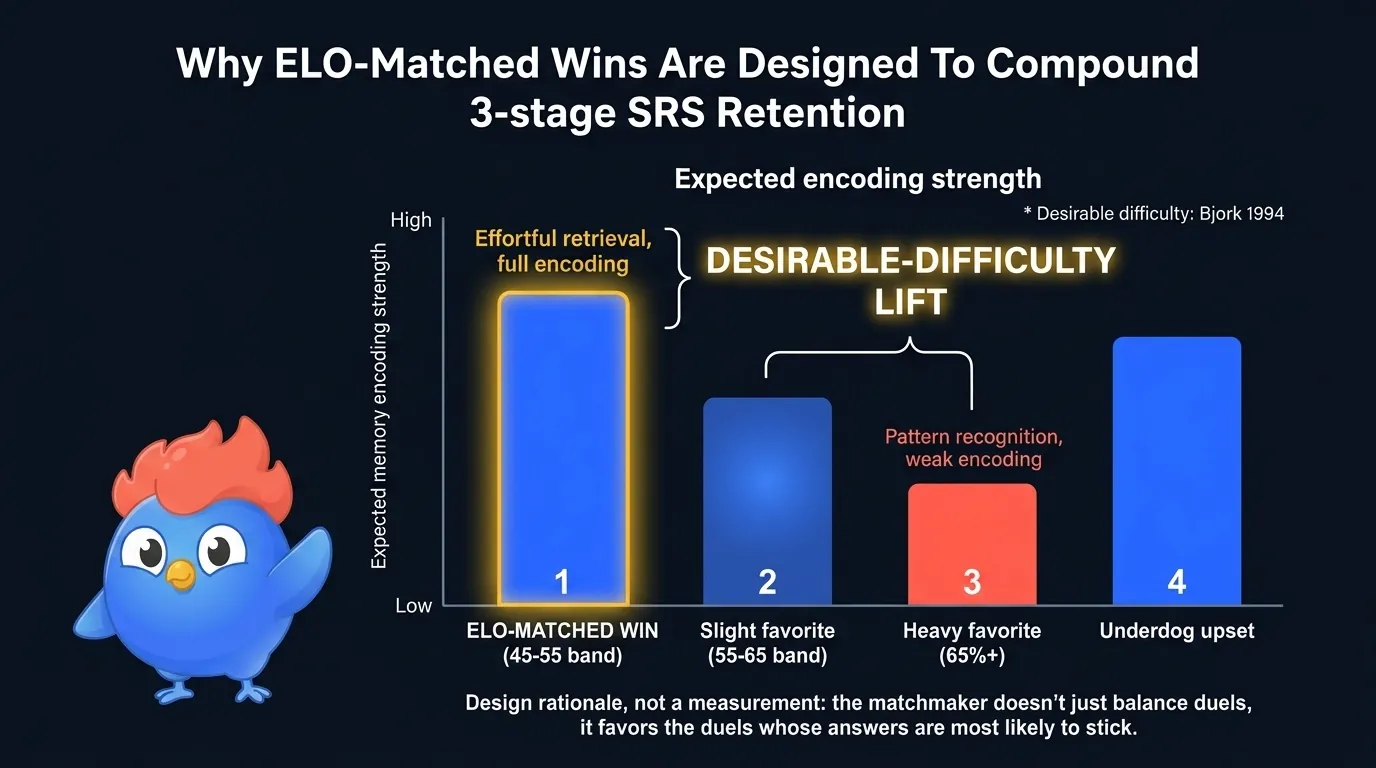 Abbildung 7: Ein kompetenz-gematchter Sieg wird durch mühevollen Abruf verdient; ein Kantersieg wird durch Mustererkennung beantwortet. Der erste ist die Zone wünschenswerter Schwierigkeit, in der das Encoding am stärksten ist.
Abbildung 7: Ein kompetenz-gematchter Sieg wird durch mühevollen Abruf verdient; ein Kantersieg wird durch Mustererkennung beantwortet. Der erste ist die Zone wünschenswerter Schwierigkeit, in der das Encoding am stärksten ist.
Der Mechanismus ist dasselbe Prinzip wünschenswerter Schwierigkeit, das sich durch diesen Artikel zieht, und es hat drei Teile. Nur einer davon ist intuitiv.
- Erregung: ein enges Duell hebt die Erregung und stärkt das neuronale Encoding
- Abrufschwierigkeit: Fragen, die du knapp richtig hast, sitzen am Rand des Abrufs, der Bjork-Zone
- Encoding-arme Kantersiege: leichte Siege antworten durch Mustererkennung, nicht Abruf, also encodiert das Gehirn kaum
Der erste Treiber ist Erregung. Ein enges Duell erzeugt moderate Erregung und stärkeres neuronales Encoding, gemäß dem zuvor behandelten Yerkes-Dodson-Prinzip. Eine korrekt beantwortete Frage in diesem Zustand encodiert dauerhafter als dieselbe Frage in einer Niedrigstress-Übungsrunde. Salehi et al. (2019) demonstrierten den Erregungs-Encoding-Effekt in Laborstudien.
Der zweite Treiber ist Abrufschwierigkeit. Die Fragen, die du in einem ausgeglichenen Duell knapp richtig hast, sitzen am Rand deiner Abruffähigkeit, der Zone, die Bjork wünschenswerte Schwierigkeit nannte. Abruf, der mit Mühe gelingt, legt stärkeres Gedächtnis an als Abruf, der leicht gelingt.
„Bedingungen, die die Erwerbsrate verlangsamen, produzieren oft die dauerhafteste Langzeitretention.“ Robert Bjork, zusammengefasst in Making Things Hard on Yourself (2011)
Der dritte Treiber ist das, worüber niemand spricht. Kantersiege sind encoding-arm. Wenn ein Spieler dominiert, antwortet er oft korrekt, ohne Abruf zu engagieren. Die richtige Antwort kommt durch Mustererkennung, durch Kategorienvertrautheit, dadurch, dass die Frage zu leicht ist. Das Gehirn encodiert diese Momente kaum, und ein späterer SRS-Check fängt die Lücke eher ab.
Deshalb haben wir den Composite-Matchmaker so gebaut, wie wir ihn gebaut haben. Es reicht nicht, enge Duelle für Engagement zu wollen. Wir wollen enge Duelle, weil sie die 3-stufige SRS-Retentionskurve mit Erinnerungen füttern, die den 7-Tage-Check überleben, statt mit leichten Siegen, die verblassen. Systeme, die für Einzelsitzungs-Cramming oder Klassenenergie gebaut sind, wie Quizlets Free-Learn-Modus mit Cap bei 5 Runden pro Set oder Kahoots host-gesteuertes Live-Format, planen diesen Check gar nicht ein.
Wichtigste Erkenntnis: ELO-Matching ist nicht nur ein Engagement-System. In LearnClash ist es ein Gedächtnisqualitäts-System, weil ein harter-aber-fairer Sieg an der Abruf-Grenze verdient wird, wo Gedächtnis konsolidiert.
Wie sich LearnClash von MOBAs und TrueSkill unterscheidet
LearnClash erbt die ELO-Formel vom Schach, die Bewertungsabweichungs-Idee von Glicko und die Composite-Bewertungs-Idee von niemandem. In LearnClash bleibt die öffentliche Bewertung als ELO. Die Inaktivitätsbehandlung nutzt intern Glicko-Stil-Abweichungswachstum. Der Matchmaker legt Kategorien-Cosinus oben drauf.
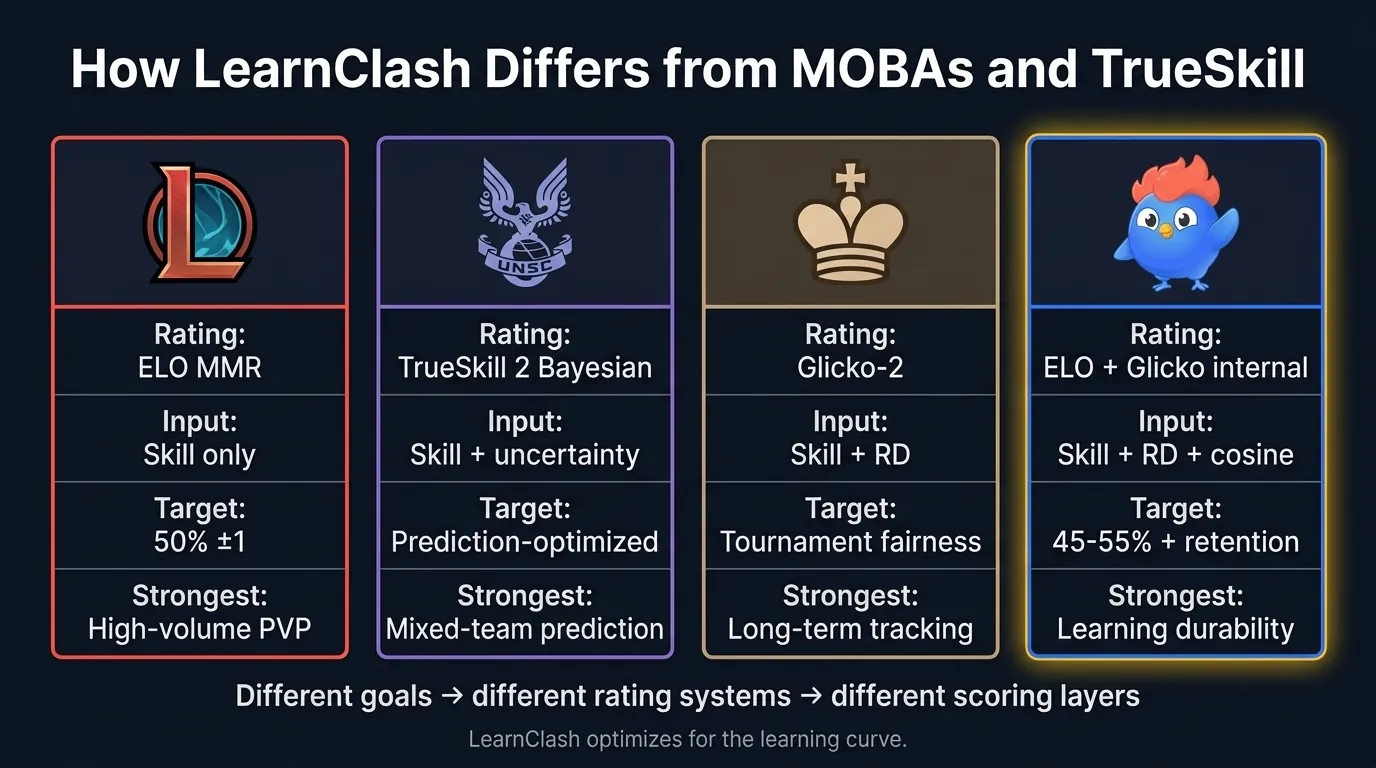 Abbildung 8: Matchmaker-Vergleich über League of Legends, Halo TrueSkill 2, Schach-Glicko-2 und LearnClash. Andere Ziele, andere Bewertungssysteme, andere Bewertungsschichten.
Abbildung 8: Matchmaker-Vergleich über League of Legends, Halo TrueSkill 2, Schach-Glicko-2 und LearnClash. Andere Ziele, andere Bewertungssysteme, andere Bewertungsschichten.
MOBAs lösen ein anderes Problem und kommen zu anderen Antworten. Der Vier-System-Vergleich:
| League of Legends | Halo TrueSkill 2 | Schach Glicko-2 | LearnClash | |
|---|---|---|---|---|
| Bewertungssystem | ELO MMR | TrueSkill 2 Bayessch | Glicko-2 | ELO + Glicko intern |
| Matchmaking-Eingabe | Nur Kompetenz | Kompetenz + Unsicherheit | Kompetenz + RD | Kompetenz + RD + Cosinus |
| Siegquoten-Ziel | 50 % (Riot-Politik) | Vorhersage-optimiert | Turnierfairness | Ausgeglichenes Band + Retention |
| Stärkste bei | Massen-PVP | Mixed-Team-Vorhersage | Langzeit-Tracking | Lerndauerhaftigkeit |
| Schwäche | Themen-blind | Hoher Rechenaufwand | Keine Kategorienkenntnis | Engere Warteschlange bei Skalierung |
League of Legends nutzt eine interne MMR getrennt vom sichtbaren Rang. Riots erklärtes Ziel ist, dass jedes Team einen 50-Prozent-Erwartungswert ±1 hat, was ihr Dev-Team 2024 bestätigte. Die 50-Prozent-Verschwörung in League-Foren spiegelt eine echte Designentscheidung wider, angewendet auf den falschen Rahmen: MOBAs zielen auf ausgeglichene Warteschlangen ab, nicht ausgeglichenes Lernen.
Microsofts TrueSkill 2 (2018) ist das mathematisch ausgefeilteste. Es behandelt jeden Spielers Kompetenz als Wahrscheinlichkeitsverteilung und aktualisiert die Varianz nach jedem Match.
Wusstest du? TrueSkill 2 wurde ursprünglich mit Match-Daten aus der Halo-2-Beta evaluiert. Das System trainierte auf Hunderten Millionen Matches, bevor es in Halo 5 ausgeliefert wurde. Es prognostiziert Ergebnisse mit 68 Prozent Genauigkeit, gegen 52 Prozent für das ursprüngliche TrueSkill.
Das Modell behandelt Teamspiel, Unentschieden und Quitting-Verhalten nativ. Der Preis ist hoher Rechenaufwand und eine öffentliche Bewertung, die für neue Spieler unvorhersagbar springt.
Schach-Glicko-2 (Mark Glickman, 1995, 2001 weiterentwickelt) fügte einen Bewertungsabweichungs-Term zum ELO-Mittelwert hinzu. RD misst, wie zuversichtlich das System gerade in deine Bewertung ist. Sie wächst nach Inaktivität, schrumpft mit regelmäßigem Spielbetrieb und lässt das System dich gegen ein breiteres Band paaren, wenn Unsicherheit hoch ist.
Wichtigste Erkenntnis: Jedes der vier Systeme optimiert für ein anderes Ziel. MOBAs optimieren für Warteschlangen-Balance. Microsoft optimiert für Vorhersage-Genauigkeit. Schach optimiert für Turnierfairness. LearnClash optimiert für die Lernkurve.
LearnClashs Composite pickt aus jedem. Die öffentliche Bewertung bleibt als ELO, weil die Markenvertrautheit und Stufen-Lesbarkeit zählen für die Spieleridentität. Das Glicko-Stil-RD-Wachstum läuft darunter, um Inaktivität abzufangen. Die Kategorien-Cosinus-Schicht ist die LearnClash-Ergänzung und der Grund, warum das Siegquoten-Band eng bleibt, statt sich in themen-getriebene Mismatches zu weiten.
Ein LearnClash-Duell und ein League-Ranglisten-Match teilen einen gemeinsamen Vorfahren und ansonsten fast nichts mehr. Andere Ziele. Andere Mathematik.
Das Fazit
ELO-Matchmaking landet LearnClash-Duelle in einem ausgeglichenen Siegquoten-Band, und dieses Band ist genau der Punkt. Die „erzwungene 50“-Klage, die MOBA-Spieler erheben, ist echte Mathematik, aber der falsche Rahmen für einen Lernkontext.
Wichtigste Erkenntnis: In LearnClash bedeutet ein enges Siegquoten-Band enge Retentionsgewinne. Ein kompetenz-gematchter Sieg wird an der Abruf-Grenze verdient, der Zone wünschenswerter Schwierigkeit, wo die 7-Tage-SRS-Bestehensquote hält und ein leichter Kantersieg verblasst.
Wähle ein Thema. Dein erstes Ranglisten-Duell dauert drei Minuten. Der Composite-Matchmaker erledigt den Rest, und was du fühlen wirst, ist der Unterschied zwischen einem Quiz, das driftet, und einem Duell, das genau in den Slot deiner Kompetenz passt, wo Gedächtnis tatsächlich entsteht. Für das Schwesterstück zur Design-Begründung, warum eine LearnClash-Practice-Runde 37 statt 50 Fragen hat, siehe die Rundzahlen-Steuer im Quiz-Design. Fordere mich heraus zu Lerntechniken →.
Häufig gestellte Fragen
Was ist eine ELO-gematchte Siegquote?
Eine ELO-gematchte Siegquote ist die Gewinnwahrscheinlichkeit, wenn beide Spieler einen engen Bewertungsabstand teilen. Wenn Matchmaking den Bewertungsabstand entfernt, haben beide Spieler ungefähr gleiche Chancen, also tendieren die Ergebnisse zu einem ausgeglichenen Band. Dieses Band visiert kompetenzbasiertes Matchmaking an, keine erzwungene Quote.
Erzwingt LearnClashs Matchmaking eine 50-Prozent-Siegquote?
Nein. LearnClash matcht Spieler nach Kompetenz, nicht durch Manipulation der Ergebnisse. Kompetenz-gematchte Gegner tendieren natürlich zu einer ausgeglichenen Siegquote, weil beide Spieler ungefähr gleiche Chancen haben. Die „erzwungene 50“-Theorie in MOBA-Foren verwechselt Korrelation mit Kausalität: ausgeglichenes ELO produziert ausgeglichene Siegquoten als Folge, nicht als Ziel.
Warum nutzt LearnClash einen 50/50-Composite aus ELO-Nähe und Kategorienüberschneidung?
Reines ELO-Matchmaking ignoriert Themenkompetenz. Ein Phönix-Geschichtsspezialist würde gegen einen Phönix-Physik-Spezialisten in der falschen Kategorie untergehen. LearnClashs 50/50-Composite gewichtet sowohl Kompetenz als auch Themenrelevanz, was Duelle lernfähig hält, ohne harten Bewertungsbereich-Filter.
Wie vergleicht sich ELO-Matchmaking mit TrueSkill oder Glicko-2?
TrueSkill 2 (Microsoft, 2018) verfolgt Kompetenzunsicherheit neben dem Bewertungsmittelwert und prognostiziert Match-Ausgänge mit 68 Prozent Genauigkeit. Glicko fügt Bewertungsabweichung hinzu, die mit Inaktivität wächst. LearnClash nutzt Glicko intern für Inaktivitätsbehandlung, behält aber die öffentliche Bewertung als ELO und ergänzt Kategorien-Cosinus, weil Lernwert von Themenübereinstimmung abhängt, nicht nur von Kompetenz.
Verbessert häufigeres Gewinnen in ELO-gematchten Duellen die Gedächtnisleistung?
Kompetenz-gematchte Duelle liegen in Bjorks Zone wünschenswerter Schwierigkeit, wo Abruf mit Mühe gelingt. Diese Mühe wandelt eine richtige Antwort in dauerhaftes Gedächtnis um, also encodiert ein harter-aber-fairer Sieg stärker als ein müheloser Kantersieg. Das 3-stufige SRS plant dann die Wiederholung, die es festigt.